

As mentioned before, agglomerative algorithms work slowly on large data sets, kmeans could not be applied to non-convex data sets, and both are not able to detect and delete outliers. Thus, density-based clustering, or DBSCAN was proposed to meet the requirements like distinction and removal of noises, dealing with data sets in arbitrary shapes and improvement in efficiency of processing data sets with large size (Ester, 2014). Since it could visualize the density distribution features of data sets, DBSCAN are widely applied to weather data analysis, geography-related fields like geo-marketing and so on. In this blog, the method of DBSCAN algorithm will be briefly introduced firstly, then an example will be exhibited, and the limitation and advantages will be discussed, finally, the properly applicable scene of DBSCAN algorithms will be concluded.
Introduction
DBSCAN, or Density-Based Spatial Clustering of Applications with Noise, is a typical density-based clustering. The main targets of DBSCAN are separating high-density areas from low-density areas and forming areas with enough density as clusters. The area with lowest density will be treated as outliers and noise.
Different from hierarchical and partitioning clustering methods, there are two importance parameters in DBSCAN method, which is epsilon (eps) and minimum points (MinPts). There are several important concepts need to be explained before introducing DBSCAN method:

















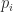






Basic Steps of DBSCAN Method
1 Prepare the data
2 Determine the paramters eps and MinPts
3 Calculate the 


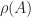

4 Find all objects density reachable from A and assign them into Cluster-A
5 Repeat steps 3-4 to every unvisited object until all objects have been visited
Example & Codes
Now we will apply DBSCAN algorithm to the test data set in R to show how it works.
##Preparing the environment and data
library("fpc")
mydata <- read_csv("test.csv", header=TRUE)
mydata <- mydata %>%
+ na.omit() %>% #delete the N/A data
+ scale() #standardize the original data
##Determine the paramters eps and MinPts
dbscan::kNNdistplot(mydata, k = 4)
abline(h = 0.15, lty = 2)

Usually we use function “kNNdistplot()” to produce such a line graph. The function fastly caculates the k-th nearest neighbour distances of each point. Since there are 950 points in the data set, and we choose k equals to 4, these gives 4*950=3800 distances in total. Then in the diagram, the y-axis is distance (which is corresponding to eps), the x-axis is the number of distances. Then, according to Kassambara (2018), the turning point in diagram indicates the optimal eps value, because a turning point means this eps value could efficiently distinguish high-density areas from low-density areas.
##Compute the cluster when eps=0.15 and MinPts=4
res.dbscan <- fpc::dbscan(mydata,
eps = 0.15,
MinPts = 4)
##Visualize the DBSCAN results
fviz_cluster(res.dbscan, data = mydata,
stand = FALSE, ellipse = FALSE,
show.clust.cent = FALSE,
geom = "point",palette = "jco",
ggtheme = theme_classic())

DBSCAN Result-I
eps=0.15 MinPt=4
In the graph, we could see that the big cluster has been clearly distinguished and most outliers have been marked.

DBSCAN Result-II
eps=0.15 MinPt=15
In this graph, only core are with high-density was isolated as a smaller cluster, the other part has been cheated as noice.
However, there should have been two clusters with different density in the data set. Though we could seperated the area with higher density in the big cluster as a new cluster if we choose larger MinPt, it is nearly impossible to recognize both clusters only with DBSCAN algorithm. The conclusion could be draw that DBSCAN could barely handle data sets with clusters of diferent density.
Advantages and Limitation
Comparing with K-means, DBSCAN algorithm behaves extremely better in distinguish clusters in any shape (especially in non-convex data). Its ability to recognize and remove outliers ensures DBSCAN perform well in environment with noise.
However, DBSCAN has its limitation as well. When the density of clusters are not uniform enough, the eps value is hard to be determined. If eps value is smaller, clusters with higher density may be divided into several clusters; but if eps value is larger, clusters with lower density may be combined. Besides, parameter configuration of DBSCAN will significantly influence the clustering results.
Conclusion
DBSCAN algorithm was proposed to overcome some inherent limitations of partitioning and hierarchical algorithms. It could not only deal with the clusters in arbitrary shapes, but also distinguish and remove noise and outliers. Also, DBSCAN algorithm approaches the clustering solution most efficiently comparing with agglomerative and kmeans algorithms, especially when the data sets are in large size.
Bibliography
Ester, M. (2014). Chapter 5: Density-Based Clustering. In: Aggarwal, C. and Reddy, C., Data clustering: algorithms and applications. 1st ed. CRC Press, pp. 111-126.
Kassambara, A. (2018). DBSCAN: Density-Based Clustering Essentials – Datanovia. [online] Datanovia. Available at: https://www.datanovia.com/en/lessons/dbscan-density-based-clustering-essentials/ [Accessed 17 Jun. 2019].
Salton, K. (2017). How DBSCAN works and why should we use it? – Towards Data Science. [online] Towards data science. Available at: https://towardsdatascience.com/how-dbscan-works-and-why-should-i-use-it-443b4a191c80 [Accessed 15 Jul. 2019].
