

Many important real-world datasets come in the form of graphs or networks: social networks, citation networks, protein-interaction networks, the World Wide Web, etc. The high interpretability of graph and the rise of deep learning has motivated to create a new intersection between deep learning and graph theory. When both these fields meet they create what we call geometric deep learning or graph neural network. It has demonstrated ground-breaking performance on many tasks that require a model to learn from graph inputs. This blog post will cover the basics of Graph Convolutional Network (GCN) and provide an intuitive explanation of how it works with some coding examples.
What is a Graph Convolutional Network?
GCN is a neural network which operates on graphs and can be understood as a simple message passing algorithm. More formally, GCNs are “connectionist models that capture the dependence of graphs via message passing between the nodes of graphs” [1]. Note that the idea of message passing in a graph is a really powerful concept as it provides the explanation for a lot of graph algorithms. In a nutshell the idea is that a node in a graph can send and receive messages along its connections with its neighbours. This can be seen as a process with two steps: first, nodes will send out a message about itself to its neighbours, and second, nodes integrate the neighbour messages and use them in some way to update itself and understand its environment. Eventually, a new representation of the node is generated and not only provide the node’s own information but also reflect the information of its neighbouring nodes. It is pretty easy, right?
Let’s make this concrete through a simple GCN. Suppose we have an input graph where there is a set of nodes, a set of edges, and our target node A. Our task here is how to learn a new representation of node A via GCN.

The process can be defined as multiple layers of a non-linear transformation of the graph structure. First, for any node in the graph, we look at it immediate neighbouring nodes. For example, here A is chosen as our node of interest, it is very straightforward to define its connected nodes which are B, C, and D as shown in Figure 1. The aggregation functions are shown by dashed lines while the non-linear activation functions are shown by the grey boxes. Let’s see how the information (message) from the neighbouring nodes can be passed through a GCN using these types of functions.
To aggregate information, first get all of the feature vectors of its connected nodes, B, C, D node in our case, and apply some aggregation function. Note that each node has a feature vector defining it (e.g. for a social network, the features can be age, gender, political leaning, etc.). You can think about a simple aggregation function like an average (shown by the dashed lines in Figure 1). This makes some intuitive sense that a node might be represented by the average of its neighbours. Next, we pass this average vector through a dense neural network layer that is a fancy way of saying that we multiply it by some weight matrix and then apply a nonlinear activation function (shown by the grey boxes in Figure 1). The final output of this dense layer is the new vector representation of this node. Now, a node is not just an average of its connected nodes but the average of its neighbouring nodes passed through some nonlinear function. This is the intuition behind the inner working of a single layer GCN.
To make network become deeper, we can do similarly with neighbouring nodes of node A (neighbour of neighbour). The subplot on the right-hand side of Figure 1 shows an architecture of a two-layer GCN. In this GCN, we do not only look at immediate neighbours of node A, for each neighbour of node A we also find its neighbours. In particular, we find that B, C, D are neighbours of node A, and we look for neighbours of node B, C, and D as well. Neighbours of node B, C, D are {A and C}, {A, B, E and F}, and {A} respectively (we use curly brackets to clearly show a set of neighbours for each node). After that for each node B, C, and D, we also perform the process of integrating information, similar as what we have done with node A.
Overall, the process of generating a new representation of node A in a two-layer GCN can be summarized as follows. After we find neighbours of neighbours of node A and we have the original input features of these nodes in the input graph, we take the aggregation of these nodes and then apply a nonlinear transformation in the first layer. The output of the first layer (Layer-1) is the new representation of node B, C, and D which have already integrated information from their neighbours. Finally, this new representation of node B, C, and D is fed as input to generate the new representation of node A in the second layer (Layer-2).
Note that we can change our target node to other nodes and generate the new embeddings for nodes as needed. Through the timesteps of message passing, the nodes know more about their own information (features) and that of neighbouring nodes. The deeper the network, the larger the local neighbourhood. You can think of it as the generalization of the receptive field of a neuron in a normal Convolutional Neural Network [3]. This network is applied convolutionally across the entire graph, always receiving features from the relevant neighbours around each node. Eventually, this helps create an even more accurate representation of the entire graph.
Now let’s look at a coding example of GCN with Python.
Coding example
- Given a graph
takes as input:
- A
input feature matrix,
, where
is the number of nodes and
is the number of input features for each node, and
- A
matrix representation of the graph structure such as the adjacency matrix
of
.
- A
- A hidden layer in GCN can be written as
where
and
is a propagation rule. Each layer
corresponds to an
feature matrix where each row is a feature representation of a node.
- The specific models then differ only in the choice of
where
is the weight matrix for layer
and
is a non-linear activation function [4].
Let’s create a simple directed graph.

And we find its adjacency matrix representation.

Since the graph has four nodes, its adjacency matrix has four rows and four columns. The first row will encode all the connections of node 1. Since node 1 is only connected with node 2 and 4, we have the value of one in the second and fourth column and zero in all the others. Then, we do the same for node 2, 3 and 4 in the next rows.
Next, we need to create some features. We generate two integer features for every node based on its index. This will help to make it easy to confirm the matrix calculations manually later.

Let’s examine the propagation rule at its most simple level. Let
- choose the weight s.t


Thus, 

The representation of each node (each row) is now a sum of its neighbours’ features. In other words, the graph convolutional layer represents each node as an aggregate of its neighbourhood. However, there are two limitations to this new representation as follows:
- The aggregated representation of a node does not include its own features. We can solve this problem by adding self-loops.
- Nodes with large degrees will have large values in their feature representation while nodes with small degrees will have small values. This can be solved by transforming the adjacency matrix by multiplying it with the inverse degree matrix
. Thus, our propagation rule will look like this:
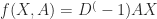
Let’s look at how we solve it using code.


We now combine the two tricks and then reintroduce the weights and activation function.

Finally, we add a nonlinear activation function, for example, ReLu as follows.

Congratulations! We have just created a single layer GCN with an adjacency matrix, input features, weights, and activation function.
Key ideas
GCNs are becoming increasingly popular given their expressive power and explicit representation of graphical data. So far, we have learned the basics of Graph Convolutional Network and the intuition behind its inner working. Most importantly, we have seen how the feature representation of a node at each layer in GCN is integrated from that of its neighbours. In addition, we performed building these networks using numpy in Python. This blog post has shed some light on GCN basics, however, it is just the tip of the iceberg. Do explore beyond this blog post and implement GCNs with practical applications.
Note: All code in here can be found on my Github account.
References
[1] Zhou, J., Cui, G., Zhang, Z., Yang, C., Liu, Z., Wang, L., Li, C. and Sun, M., 2018. Graph neural networks: A review of methods and applications. arXiv preprint arXiv:1812.08434.
[2] A tutorial on Representation Learning on Networks.
[3] A discussion post on Graph Convolutional Neural Networks by Ferenc Huszar.
[4] A blog post on Graph Convolutional Neural Networks by Thomas Kipf.
[5] A blog post on Introduction about Graph Convolutional Neural Networks by Tobias Skovgaard Jepsen.
